|
FACS Overview
Fully Automatic Face Detection and Expression Recognition The Facial Action Coding System
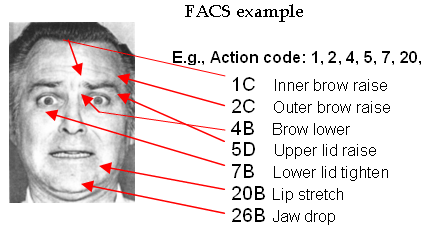
In order to objectively capture the richness and complexity of facial expressions, behavioral scientists have found it necessary to develop objective coding standards. The Facial Action Coding System (FACS) developed Ekman and Friesen (1978) is arguably the most comprehensive and influential of such standards. FACS is based on the anatomy of the human face, and codes expressions in terms of component movements, called “action units” (AUs). Ekman and Friesen defined 46 AUs to describe each independent movement of the face. FACS measures all visible facial muscle movements, including head and eye movements, and not just those presumed to be related to emotion or any other human state. When learning FACS, a coder is trained to identify the characteristic pattern of bulges, wrinkles, and movements for each facial AU. The AUs approximate individual facial muscle movements but there is not always a 1:1 correspondence. For example, the frontalis muscle which covers the forehead does not always move as one unit, as the medial portion can raise just the inner corners of the eyebrows, whereas the lateral portion raises just the outer portion Thus, the medial and lateral portions of the frontalis muscle are scored as separate AUs (AU 1 for medial, AU 2 for lateral). One would look for raised inner corner of eyebrows, and horizontal wrinkles in the middle of the forehead, to score this medial frontalis action. Likewise, some facial muscle movements seem to co-occur, as in the 3 muscles that produce the brow furrow (AU 4). The FACS coding manual provides detailed descriptions of all the appearance changes occurring with a given action unit. FACS typically scores the beginning, end, peak frame and intensity at the peak of each facial action (on an A to E scale; see FIGURE above). FACS has been used to verify the physiological presence of emotion in a number of studies, with very high levels (over 75%) of inter-coder agreement (e.g., Sayette, Cohn, Wertz, Perrott, & Parrott, 2001; Ekman, Friesen, & Ancoli, 1980; Ekman, Levenson, & Friesen, 1983; Ekman, Davidson, & Friesen, 1990; Levenson, Ekman, & Friesen, 1990; Ekman, Friesen, & O’Sullivan, 1988). Because it is comprehensive, FACS also allows for the discovery of new patterns related to emotional or situational states. For example, Ekman et al (1990) and Davidson et al (1990) found using FACS that smiles that featured both orbicularis oculi (AU6), as well as zygomatic major action (AU12), were correlated with self-reports of enjoyment, as well as different patterns of brain activity, whereas smiles that featured only zygomatic major (AU12) were not. This kind of objective and comprehensive coding of facial expression with FACS has predicted successful coping with traumatic loss (Bonnano & Keltner, 1997), the onset and remission of depression, schizophrenia, and other psychopathology (Ekman & Rosenberg, 1997), has discriminated suicidally from non-suicidally depressed patients (Heller & Haynal, 1994), and predicted transient myocardial ischemia in coronary patients (Rosenberg et al., 2001). FACS has also been able to identify patterns of facial activity involved in alcohol intoxication that observers not trained in FACS failed to note (Sayette, Smith, Breiner, & Wilson, 1992). Finally, it has discovered various patterns reliably related to deception, at about 80% accuracy (Ekman, 2001; Ekman et. al., 1988; Ekman, O’Sullivan, Friesen, & Scherer, 1991; Frank & Ekman, 1997). Although FACS is an ideal system for the behavioral analysis of facial action patterns, applying FACS to videotaped behavior is currently done by hand and its laborious nature has been identified as one of the main obstacles to doing research on emotion (Frank, 2002, Ekman et al, 1993). Currently, FACS coding is performed by trained experts who make perceptual judgments of video sequences in a frame by frame fashion. It requires approximately 100 hours of self-instructional training for a person to make these judgments reliably, with reliability determined by passing a standardized test. Once trained, it typically takes three hours to code one minute of videotaped behavior. Furthermore, although humans can be trained to code reliably the morphology of facial expressions (which muscles are active) it is very difficult for them to code the dynamics of the expression (the activation and movement patterns of the muscles as a function of time). There is good evidence suggesting that such expression dynamics, not just morphology, may provide important information as to the presence of an emotion (Ekman & Friesen, 1982). For example, spontaneous “smile” expressions that correlate significantly with self-reports of positive emotions have a fast and smooth onsets, with distinct facial actions peaking simultaneously, whereas posed smile expressions have onsets that tend to be slow and jerky, and the actions typically do not peak simultaneously (Frank, Ekman, & Friesen, 1993; Schmidt, Cohn, & Tian, 2003). Recent advances in computer vision open up the possibility of automatic coding of facial expressions at the level of detail required for such behavioral studies. We are on the verge of creating a fully automated FACS coding system that is ready to be released and implemented by other research labs. An automated system will unleash a great amount of research energy toward understanding human emotion, human anatomy and physiology, the cognitive neuroscience of emotional expression, as well as the dynamic properties of human one-on-one interaction and the give and take between individuals which is often signaled in subtle, often imperceptible ways (e.g., Chartrand & Bargh, 1999). An Automated FACS system would have a tremendous impact on basic research by making facial expression measurement more accessible as a behavioral measure, and by providing data on the dynamics of facial behavior at a resolution that was previously unavailable. Such systems would also lay the foundations for computers that can understand this critical aspect of human communication. Computer systems with this capability have a wide range of applications in video compression, education, behavioral science, mental health, human-computer interaction, homeland security, and any context in which it is important to monitor the emotional well being and paralinguistic communication of people (See Picard, 1997 for a discussion).
|